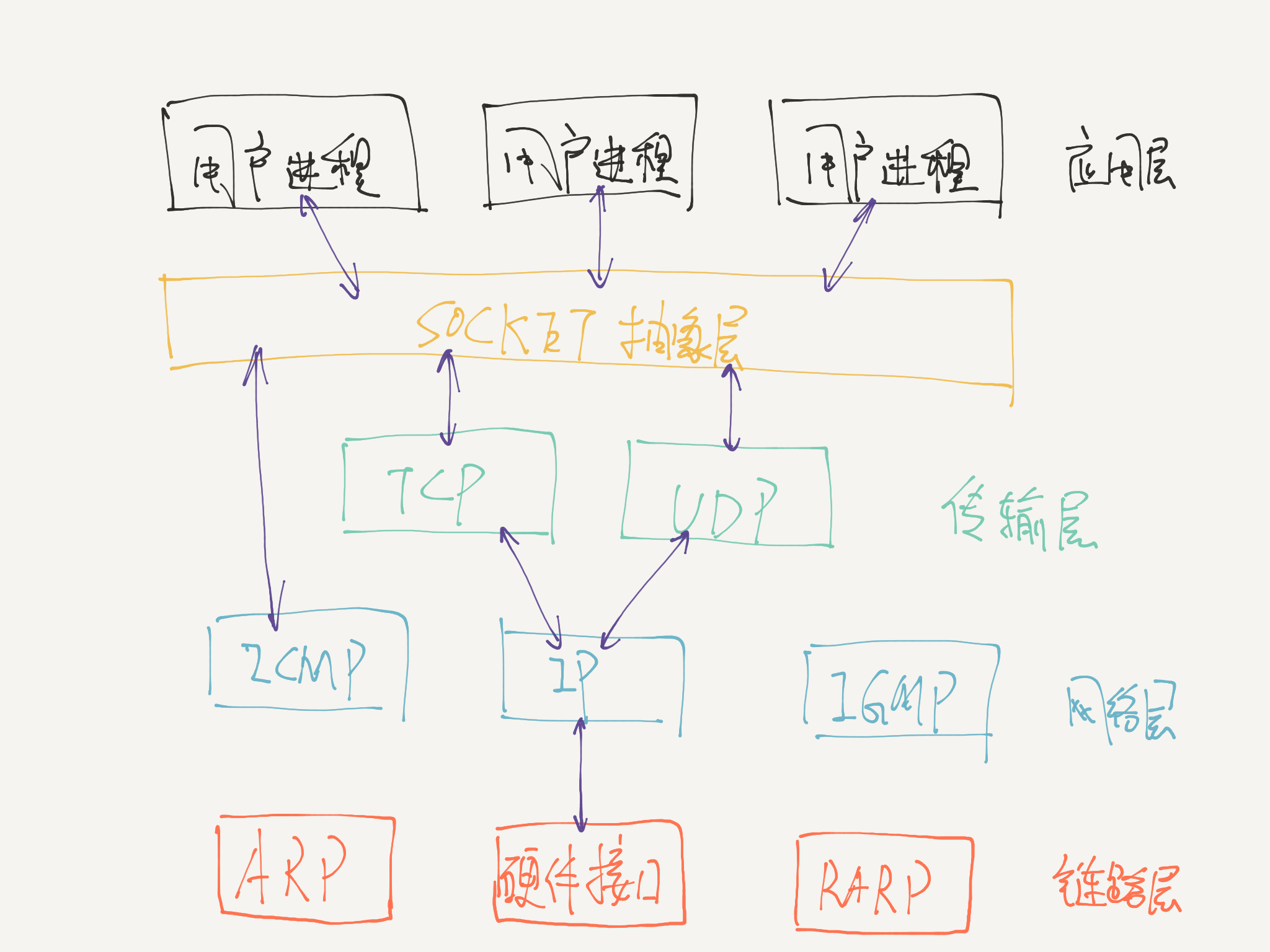
Python Version: 3.5+
__init__ 构造方法,每个对象被实例化出来的时候都将首先去执行__init__方法
1 2 3 class A : def __init__ (self) : print("在创建对象的时候会首先自动执行__init__" )
__del__ 析构方法,每个对象在被垃圾回收机制回收之前执行的方法
1 2 3 class A : def __del__ (self) : print("在对象销毁之前会执行__del__" )
__doc__ 类的描述信息
1 2 3 class A : """我是A类的描述信息""" pass
__module__ 表示当前操作的对象在哪个模块
1 2 3 class A : """我是A类的描述信息""" pass
1 2 3 from lib import Aa = A() print(a.__module__)
__class__ 表示当前操作的对象的类是什么
1 2 3 4 5 class A : pass a = A() print(a.__class__)
__call__ 类名后面加括号表示创建一个对象;如果在对象后面加括号,就需要使用__call__方法了,如果不定义这个方法,在执行对象()的时候就会报错
1 2 3 4 5 6 7 8 9 10 class A : def __call__ (self, *args, **kwargs) : print("call" ) a = A() a() ------------ call
创建对象的时候首先执行__init__,在对象被调用的时候执行__call__
也可以在一行执行
__str__ print对象的时候显示的内容
1 2 3 4 5 6 7 8 class A : pass a = A() print(a) ------------ <__main__.A object at 0x101b77128 >
在没有定义__str__的情况下,输出的是a对象的内存地址信息
1 2 3 4 5 6 7 8 9 class A : def __str__ (self) : return "A~" a = A() print(a) ------------ A~
str的应用实例
1 2 3 4 5 6 7 8 9 10 11 12 class B : def __init__ (self, name) : self.name = name def __str__ (self) : return self.name b = B("ps" ) print(b) ------------ ps
str类型转换
1 2 3 4 5 6 7 8 9 10 class B : def __init__ (self, name) : self.name = name def __str__ (self) : return self.name b = B("ps" ) ret = str(b) print(ret)
str(b)和print()都会自动去调用b对象中的__str__方法
__dict__ 对象的dict 在对象中默认已经有dict,不需要自定义。该方法用来获取对象中所有封装的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name b = B("ps" , 26 ) print(b.__dict__) ------------ {'age' : 26 , 'name' : 'ps' }
类的dict 列出类中所有可以调用的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name b = B("ps" , 26 ) print(B.__dict__) ------------ {'__weakref__' : <attribute '__weakref__' of 'B' objects>, '__module__' : '__main__' , '__str__' : <function B.__str__ at 0x10137b730 >, '__init__' : <function B.__init__ at 0x10137b6a8 >, '__doc__' : None , '__dict__' : <attribute '__dict__' of 'B' objects>}
__add__ 当执行一个对象 + 一个对象的时候,就会自动去执行这个方法
注意,执行的是第一个对象的add方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class A : def __init__ (self, num) : self.num = num def __add__ (self, other) : return self.num + other.num class B : def __init__ (self, num) : self.num = num a = A(5 ) b = B(9 ) c = a + b print(c)
__getitem__ __setitem__ __delitem__ 用于索引操作,如字典。以上分别表示获取、设置、删除数据
1 2 3 4 d = {"k" : "v" } print(d["k" ]) d["k" ] = "vv" del d["k" ]
上面的代码展示了一个字典对象的取值、赋值和删除的操作。在自定义的类中,也可以实现类似于字典这样的操作
对象后面加小括号是执行__call__方法,那么对象后面加中括号又是怎样处理的呢?
使用key进行的操作 取值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print("执行了getitem方法" , item) b = B("ps" , 26 ) b["name" ] ------------ 执行了getitem方法 name
赋值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print("执行了getitem方法" , item) def __setitem__ (self, key, value) : print("你要为%s重新赋值为%s" % (key, value)) b = B("ps" , 26 ) print(b.name) b["name" ] = "lr" ------------ ps 你要为name重新赋值为lr
删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print("执行了getitem方法" , item) def __setitem__ (self, key, value) : print("你要为%s重新赋值为%s" % (key, value)) def __delitem__ (self, key) : print("你要删除%s" % key) b = B("ps" , 26 ) del b["age" ]------------ 你要删除age
在web开发中,自定义session框架的时候会用到
使用下标进行的操作 使用下标和使用key的形式类似,使用key, item接收的是一个字符串,使用下标, item接收的是一个int类型的数字,可以在方法体内通过判断传递过来数据的数据类型来进行对应的操作
使用切片的操作 1 2 l = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ] l[1 :5 :2 ]
在Python2.x中使用__getslice__ __setslice__ __delslice__来实现切片的操作,但是Python3.x中被遗弃,所有切片的功能都集中在了__getitem__ __setitem__ __delitem__中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print(type(item)) def __setitem__ (self, key, value) : print("你要为%s重新赋值为%s" % (key, value)) def __delitem__ (self, key) : print("你要删除%s" % key) b = B("ps" , 26 ) b["name" ] b[1 ] b[1 :5 :2 ] ------------ <class 'str '> <class 'int '> <class 'slice '>
item为slice时表示调用了切片的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print("起点索引" , item.start) print("终点索引" , item.stop) print("步长" , item.step) return "haha" def __setitem__ (self, key, value) : print("你要为%s重新赋值为%s" % (key, value)) def __delitem__ (self, key) : print("你要删除%s" % key) b = B("ps" , 26 ) ret = b[1 :5 :2 ] print(ret) ------------ 起点索引 1 终点索引 5 步长 2 haha
相对应的,取值可以通过判断item的类型做相应的操作,赋值和删除也可以通过判断key的类型来进行想对应的切片操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class B : def __init__ (self, name, age) : self.name = name self.age = age def __str__ (self) : return self.name def __getitem__ (self, item) : print("起点索引" , item.start) print("终点索引" , item.stop) print("步长" , item.step) return "haha" def __setitem__ (self, key, value) : print("起点索引" , key.start) print("终点索引" , key.stop) print("步长" , key.step) print("新值为" , value) def __delitem__ (self, key) : print("起点索引" , key.start) print("终点索引" , key.stop) print("步长" , key.step) b = B("ps" , 26 ) print("切片取值" ) ret = b[1 :5 :2 ] print("切片赋值" ) b[1 :5 :2 ] = "hehe" print("切片删除" ) print(ret) del b[1 :5 :2 ]------------ 切片取值 起点索引 1 终点索引 5 步长 2 切片赋值 起点索引 1 终点索引 5 步长 2 新值为 hehe 切片删除 haha 起点索引 1 终点索引 5 步长 2
__iter__ 一个自定义类实例化的对象,默认是不可迭代的,在类中使用__iter__方法后,对象就变成了可迭代对象。当对象被迭代时,会自动调用iter方法
1 2 3 4 5 6 7 8 9 10 11 12 class A : pass a = A() for i in a: print(i) ------------ Traceback (most recent call last): File "/Users/lvrui/PycharmProjects/untitled/8/c8.py" , line 5 , in <module> for i in a: TypeError: 'A' object is not iterable
1 2 3 4 5 6 7 8 9 10 11 class A : def __iter__ (self) : return iter([1 , 2 ]) a = A() for i in a: print(i) ------------ 1 2
1 2 3 4 5 6 7 8 9 10 11 12 class A : def __iter__ (self) : yield 1 yield 2 a = A() for i in a: print(i) ------------ 1 2
先去a对象中找到iter方法执行,并拿到返回值进行迭代
1 2 3 4 5 6 class A (object) : def __init__ (self) : pass a = A()
上述代码中,a 是通过 A 类实例化的对象,其实,不仅 a 是一个对象,A类本身也是一个对象,因为在Python中一切事物都是对象。
如果按照一切事物都是对象的理论:a对象是通过执行A类的构造方法创建,那么A类对象应该也是通过执行某个类的构造方法创建。
1 2 print type(a) print type(A)
所以,a对象是A类的一个实例,A类对象是type类的一个实例,即:A类对象是通过type类的构造方法创建
那么,创建类就可以有两种方式:
1 2 3 4 class A (object) : def func (self) : print("ps" )
1 2 3 4 5 6 7 def func (self) : print("ps" ) A = type('A' ,(object,), {'func' : func})
–> 类是由type类实例化产生
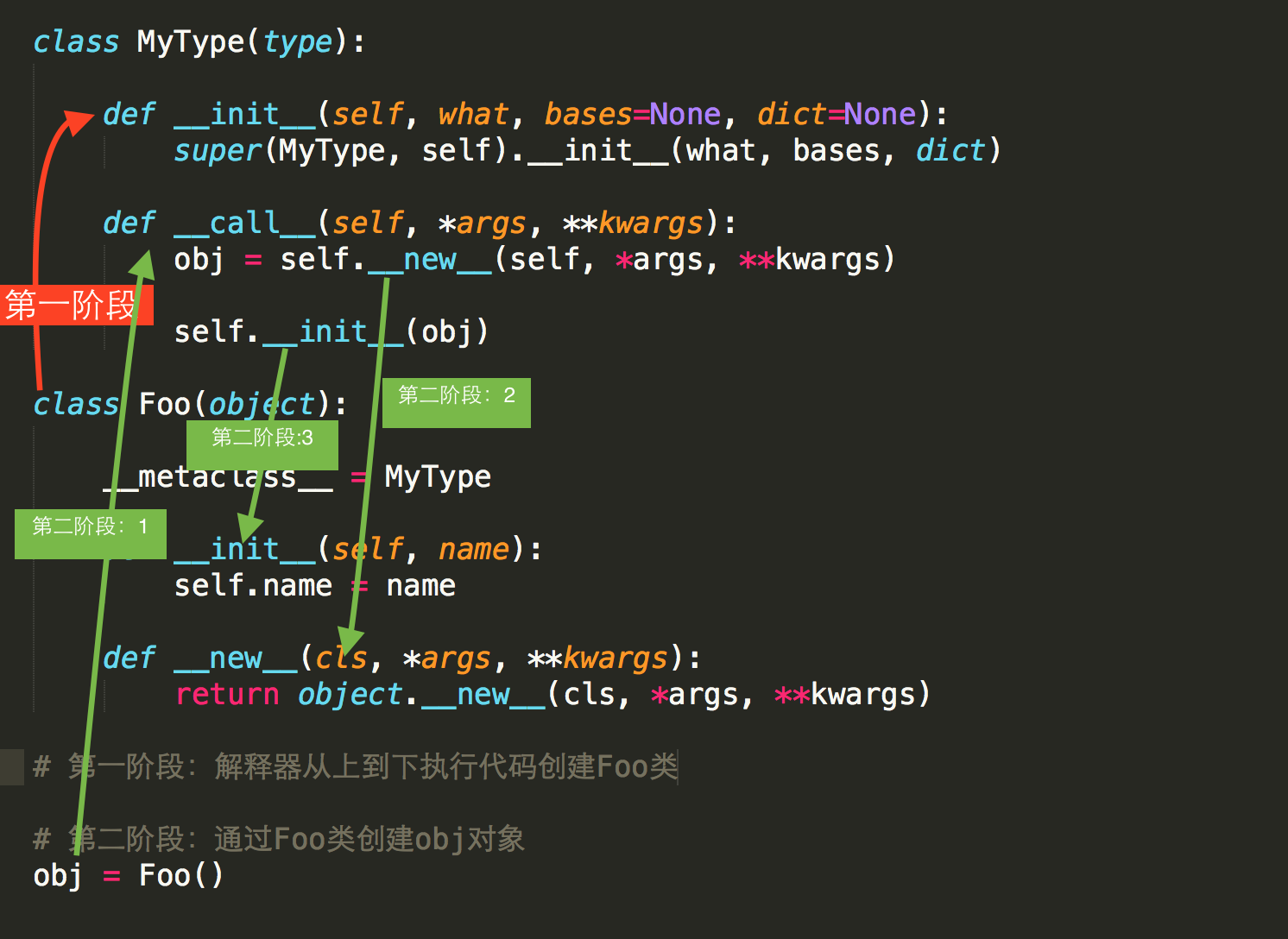
那么问题来了,类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性__metaclass__ 其用来表示该类由谁来实例化创建,所以,我们可以为__metaclass__设置一个type类的派生类,从而查看类创建的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class MyType (type) : def __init__ (self, what, bases=None, dict=None) : super(MyType, self).__init__(what, bases, dict) def __call__ (self, *args, **kwargs) : obj = self.__new__(self, *args, **kwargs) self.__init__(obj) class A (object) : __metaclass__ = MyType def __init__ (self, name) : self.name = name def __new__ (cls, *args, **kwargs) : return object.__new__(cls, *args, **kwargs) a = A()