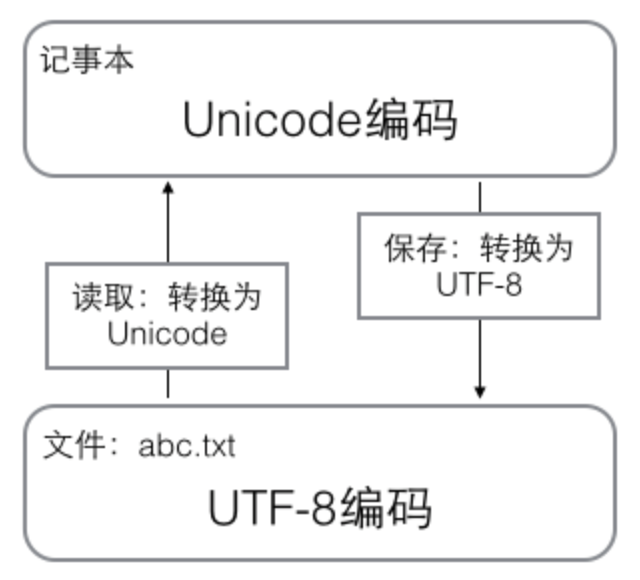
Never use utf8 in MySQL — always use utf8mb4 instead. Updating your databases and code might take some time, but it’s definitely worth the effort. Why would you arbitrarily limit the set of symbols that can be used in your database? Why would you lose data every time a user enters an astral symbol as part of a comment or message or whatever it is you store in your database? There’s no reason not to strive for full Unicode support everywhere. Do the right thing, and use utf8mb4. 🍻
mysql> SET GLOBAL validate_password_policy = LOW; Query OK, 0 rows affected (0.00 sec)
mysql> create user 'repl' identified by '12345678'; Query OK, 0 rows affected (0.05 sec)
mysql> grant replication slave on *.* to repl@'%'; Query OK, 0 rows affected (0.02 sec)
查看主库与从库GTID状态
1 2 3 4 5 6 7
mysql> show variables like 'gtid_mode'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | gtid_mode | ON | +---------------+-------+ 1 row in set (0.01 sec)
> yum remove -y mysql > cd /usr/local/src/ > wget http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm > rpm -ivh mysql57-community-release-el7-8.noarch.rpm 警告:mysql57-community-release-el7-8.noarch.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY 准备中... ################################# [100%] 正在升级/安装... 1:mysql57-community-release-el7-8 ################################# [100%] > yum install -y mysql-server > systemctl start mysqld > systemctl status mysqld ● mysqld.service - MySQL Server Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled) Active: active (running) since 五 2016-08-19 09:30:24 EDT; 29s ago Process: 105136 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid $MYSQLD_OPTS (code=exited, status=0/SUCCESS) Process: 105049 ExecStartPre=/usr/bin/mysqld_pre_systemd (code=exited, status=0/SUCCESS) Main PID: 105138 (mysqld) CGroup: /system.slice/mysqld.service └─105138 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
8月 19 09:30:16 localhost.localdomain systemd[1]: Starting MySQL Server... 8月 19 09:30:24 localhost.localdomain systemd[1]: Started MySQL Server. > cat /var/log/mysqld.log| grep "temporary password" 2016-08-19T13:30:20.547835Z 1 [Note] A temporary password is generated for root@localhost: TVu7ouUi>55l > mysql -uroot -p Enter password:TVu7ouUi>55l Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.14
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h'forhelp. Type '\c' to clear the current input statement.
mysql>
设置root用户密码
MySQL5.7默认的密码复杂度为:大小写字母+数字+特殊符号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
mysql> alter user user() identified by 'w{YQW6L;Dsf6vw'; Query OK, 0 rows affected (0.00 sec)
mysql> mysql> SHOW VARIABLES LIKE 'validate_password%'; +--------------------------------------+--------+ | Variable_name | Value | +--------------------------------------+--------+ | validate_password_dictionary_file | | | validate_password_length | 8 | | validate_password_mixed_case_count | 1 | | validate_password_number_count | 1 | | validate_password_policy | MEDIUM | | validate_password_special_char_count | 1 | +--------------------------------------+--------+ 6 rows in set (0.01 sec)
LOW policy tests password length only. Passwords must be at least 8 characters long.
MEDIUM policy adds the conditions that passwords must contain at least 1 numeric character, 1 lowercase and uppercase character, and 1 special (nonalphanumeric) character.
STRONG policy adds the condition that password substrings of length 4 or longer must not match words
在默认MEDIUM的策略下,修改密码为:12345678会报错
1 2
mysql> alter user user() identified by '12345678'; ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
修改MySQL密码检查策略
1 2 3 4 5
mysql> SET GLOBAL validate_password_policy = LOW; Query OK, 0 rows affected (0.00 sec)
mysql> alter user user() identified by '12345678'; Query OK, 0 rows affected (0.00 sec)
mysql> select * from testint; +-------------+-----------------------+ | a | b | +-------------+-----------------------+ | 00000000001 | 000000000000000000001 | +-------------+-----------------------+ 1 row in set (0.00 sec)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 默认情况下数字前面不会补零 mysql> create table testint (a int(11), b int(21)); Query OK, 0 rows affected (0.03 sec)
在使用ssh客户端连接远程主机时,如果远程主机是首次访问,会提示添加远程主机的指纹信息;如果远程主机的信息发生变更,则不能连接建立连接,报REMOTE HOST IDENTIFICATION HAS CHANGED!的错误,此时需要手动去~/.ssh/known_hosts中删除相关主机的指纹信息,重新保存才可建立连接