一般情况下,我们会设置MySQL默认的字符编码为utf8,但是近些年来,emoji表情的火爆使用,给数据库带来了意外的错误,就是emoji的字符集已经超出了utf8的编码范畴😄
令人抓狂的字符编码问题 谈到字符编码问题,会让很多人感到头疼,这里不在深究各个字符编码的特点和理论,这里只说下Unicode和utf8字符编码的关系
1 2 3 4 5 6 7 Unicode是编码字符集,而UTF-8就是字符编码,即Unicode规则字库的一种实现形式。 随着互联网的发展,对同一字库集的要求越来越迫切,Unicode标准也就自然而然的出现。 它几乎涵盖了各个国家语言可能出现的符号和文字,并将为他们编号。 详见:Unicode on Wikipedia。 Unicode的编号从0000开始一直到10FFFF共分为16个Plane,每个Plane中有65536个字符。 而UTF-8则只实现了第一个Plane,可见UTF-8虽然是一个当今接受度最广的字符集编码, 但是它并没有涵盖整个Unicode的字库,这也造成了它在某些场景下对于特殊字符的处理困难
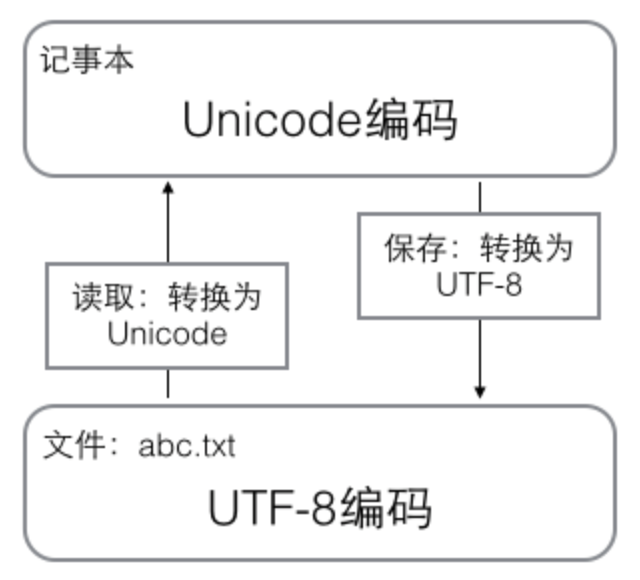
简单的说在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
emoji是Unicode编码,在MySQL中使用utf8编码无法正常显示emoji的表情,为了解决这个问题,MySQL在5.5.3版本之后,引进了新的字符编码utf8mb4,本篇文章主要介绍如何将已经是utf8的database切换到utf8mb4字符编码
什么是utf8mb4 utf8mb4最明显的好处是解决了苹果挖的坑-推广了emoji表情。utf8mb4解决了MySQL数据库存储emoji表情的问题
utf8mb4是utf8的超集,理论上由utf8升级到utf8mb4字符编码没有任何兼容问题
升级utf8到utf8mb4 1. 备份 安全第一,备份所有需要升级字符编码的数据库
可以将库dump出来
如果是虚拟机,可以给整个主机做快照
2. 升级 utf8mb4是MySQL5.5.3版本之后支持的字符集,so,如果你需要使用这个字符集,前提条件是你的MySQL版本必须 >= 5.5.3
3. 修改 在MySQL中,可以为一个database设置字符编码,可以为一张表设置字符编码,甚至可以为某一个字段设置字符编码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; + | Variable_name | Value | + | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8_general_ci | + 10 rows in set (0.01 sec) mysql>
1 2 3 4 5 6 7 8 9 mysql> show create database polarsnow; + | Database | Create Database | + | polarsnow | CREATE DATABASE `polarsnow` | + 1 row in set (0.00 sec)mysql>
1 2 3 4 5 6 7 8 9 mysql> show create table ps; +-------+---------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+---------------------------------------------------------------------------------------------+ | ps | CREATE TABLE `ps` ( `name` varchar(100) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 | +-------+---------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
1 2 3 4 5 6 7 mysql> show full columns from ps; + | Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment | + | name | varchar (100 ) | utf8_general_ci | YES | | NULL | | select ,insert ,update ,references | | + 1 row in set (0.00 sec)
修改database默认的字符集 ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 mysql> ALTER DATABASE polarsnow CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; Query OK, 1 row affected (0.03 sec) mysql> show create database polarsnow; + | Database | Create Database | + | polarsnow | CREATE DATABASE `polarsnow` | + 1 row in set (0.00 sec)mysql> show tables ; + | Tables_in_polarsnow | + | ps | + 1 row in set (0.00 sec) mysql> show create table ps; + | Table | Create Table | + | ps | CREATE TABLE `ps` ( `name` varchar (100 ) DEFAULT NULL ) ENGINE =InnoDB DEFAULT CHARSET =utf8 | + 1 row in set (0.00 sec)mysql> show full columns from ps; + | Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment | + | name | varchar (100 ) | utf8_general_ci | YES | | NULL | | select ,insert ,update ,references | | + 1 row in set (0.00 sec)mysql> create table test_tb2 (tb2 varchar (100 ) ); Query OK, 0 rows affected (0.21 sec) mysql> show tables; + | Tables_in_polarsnow | + | ps | | test_tb2 | + 2 rows in set (0.00 sec) mysql> show create table test_tb2; + | Table | Create Table | + | test_tb2 | CREATE TABLE `test_tb2` ( `tb2` varchar (100 ) COLLATE utf8mb4_unicode_ci DEFAULT NULL ) ENGINE =InnoDB DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_unicode_ci | + 1 row in set (0.00 sec)mysql>
可以看到,虽然修改了database的字符集为utf8mb4,但是实际只是修改了database新创建的表,默认使用utf8mb4,原来已经存在的表,字符集并没有跟着改变,需要手动为每张表设置字符集
修改table的字符集
只修改表默认的字符集 ALTER TABLE table_name DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修改表默认的字符集和所有字符列的字符集 ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 mysql> show create table ps; + | Table | Create Table | + | ps | CREATE TABLE `ps` ( `name` varchar (100 ) DEFAULT NULL ) ENGINE =InnoDB DEFAULT CHARSET =utf8 | + 1 row in set (0.00 sec)mysql> show full columns from ps; + | Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment | + | name | varchar (100 ) | utf8_general_ci | YES | | NULL | | select ,insert ,update ,references | | + 1 row in set (0.00 sec)mysql> ALTER TABLE ps CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; Query OK, 0 rows affected (0.38 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show create table ps; + | Table | Create Table | + | ps | CREATE TABLE `ps` ( `name` varchar (100 ) COLLATE utf8mb4_unicode_ci DEFAULT NULL ) ENGINE =InnoDB DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_unicode_ci | + 1 row in set (0.00 sec)mysql> show full columns from ps; + | Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment | + | name | varchar (100 ) | utf8mb4_unicode_ci | YES | | NULL | | select ,insert ,update ,references | | + 1 row in set (0.00 sec)mysql>
修改column默认的字符集 ALTER TABLE table_name CHANGE column_name column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
注:VARCHAR(191) 根据字段实例的类型填写
4. 检查字段的最大长度和索引列
由于从utf8升级到了utf8mb4,一个字符所占用的空间也由3个字节增长到4个字节,但是我们当初创建表时,设置的字段类型以及最大的长度没有改变。例如,你在utf8下设置某一字段的类型为TINYTEXT, 这中字段类型最大可以容纳255字节,三个字节一个字符的情况下可以容纳85个字符,四个字节一个字符的情况下只能容纳63个字符,如果原表中的这个字段的值有一个或多个超过了63个字符,那么转换成utf8mb4字符编码时将转换失败,你必须先将TINYTEXT更改为TEXT等更高容量的类型之后才能继续转换字符编码
在InnoDB引擎中,最大的索引长度为767字节,三个字节一个字符的情况下,索引列的字符长度最大可以达到255,四个字节一个字符的情况下,索引的字符长度最大只能到191。如果你已经存在的表中的索引列的类型为VARCHAR(255)那么转换utf8mb4时同样会转换失败。你需要先将VARCHAR(255)更改为VARCHAR(191)才能继续转换字符编码
5. 修改配置文件 SET NAMES utf8 COLLATE utf8_unicode_ci becomes SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 > vim /etc/my.cnf [client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci > service mysqld restart
检查修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; + | Variable_name | Value | + | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | collation_connection | utf8mb4_unicode_ci | | collation_database | utf8mb4_unicode_ci | | collation_server | utf8mb4_unicode_ci | + 10 rows in set (0.00 sec)
注:character_set_system 一直都会是 utf8,不能被更改
6. 修复&优化所有数据表 1 > mysqlcheck -u root -p --auto-repair --optimize --all-databases
总结 不要在MySQL上使用utf8字符编码,推荐使用utf8mb4,至于为什么,引用国外友人的一段话:
Never use utf8 in MySQL — always use utf8mb4 instead. Updating your databases and code might take some time, but it’s definitely worth the effort. Why would you arbitrarily limit the set of symbols that can be used in your database? Why would you lose data every time a user enters an astral symbol as part of a comment or message or whatever it is you store in your database? There’s no reason not to strive for full Unicode support everywhere. Do the right thing, and use utf8mb4. 🍻
参考文档