执行go协程时, 是没有返回值的, 这时候需要用到go语言中特色的channel来获取到返回值. 通过channel拿到返回值有两种处理形式, 一种形式是具有go风格特色的, 即发送给一个
for channel或select channel的独立goroutine中, 由该独立的goroutine来处理函数的返回值. 还有一种传统的做法, 就是将所有goroutine的返回值都集中到当前函数, 然后统一返回给调用函数.
BufferedChannel&sync.WaitGroup实现并发数控制
利用带缓存的channel和WaitGroup, 可以实现对goroutine的并发数控制. 使用起来非常简单
go语言zap日志自定义输出
前篇文章中介绍了zap日志包的basic用法, 在
zap.Config的配置中, 有OutputPaths和ErrorOutputPaths分别可以指定日志输出目标, 一般情况下, 日志会输出到stdoutstderr或 本地文本文件. 本篇文章介绍自定义协议的日志输出目标
go语言优秀的日志包zap基础自定义配置用法
zap 的官方案例中, 介绍了三种使用方式, 分别是
AdvancedConfigurationBasicConfiguration和Presets本篇文章介绍 zap 包的 BasicConfiguration 用法
go语言优秀的日志包zap预置函数用法
zap 和 logrus 是 go 语言中日志包的佼佼者. 两者都推荐使用结构化的日志打印, 从速度上来说, zap 要比 logrus 快很多. zap 的官方案例中, 介绍了三种使用方式, 分别是
AdvancedConfigurationBasicConfiguration和Presets本篇文章介绍 zap 包的 Presets 用法
go语言中的类型和别名
在go语言中, 定义类型有两种方式, 一种是定义一个全新的类型, 一种是定义一个类型的别名.
语法区别
定义全新的数据类型
1 | type A int |
定义类型的别名
1 | type B = int |
两者语法上的区别仅仅是有没有=
赋值区别
1 | package main |
使用区别
如果你给一个非本地的数据类型定义方法时, 编译时会报错, IDE也会提示你错误
1 | package main |
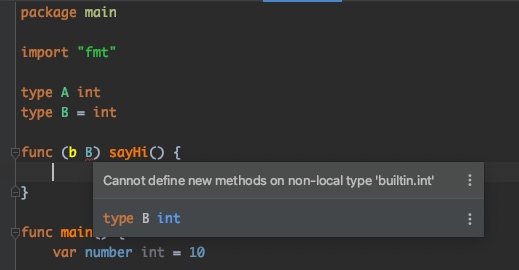
错误提示: Cannot define new methods on non-local type ‘builtin.int’
但是如果你用的是你自定义的数据类型的别名, 是完全可以的
1 | type C struct { |
别名不仅拥有原数据类型的全部方法, 而且在别名中定义的方法, 会自动出现在原数据类型的方法中, 原类型也可以正常调用别名定义的方法. 因为别名的本质, 就是同一数据类型, 只是名字不同罢了
1 | package main |
执行结果:
1 | Hello |
而定义全新类型则跟别名的情况完全不同. 定义全新的类型, 不管你用的是不是本地类型, 都可以为新的类型添加方法. 以下操作是合法的
1 | type A int |
在全新类型下定义的方法, 不会出现在原类型上. 原类型的方法也不会出现在新类型中.
1 | type C struct { |
执行结果:
1 | ./a2.go:25:3: c.sayHi undefined (type C has no field or method sayHi) |
新类型的应用场景
在使用有限状态机的情况下, 我们可以为能预见的所有状态定义为一个单独的类型. 拿一台kvm的虚拟机来说. 描述虚拟机的运行状态, 就是一种有限状态机的场景. 虚拟机可以是如下任意一种状态:
- up
- down
- poweringup
- poweringdown
- rebooting
- shutingdown
再比如给虚拟机创建的磁盘文件, 可以有以下格式可选:
- cow
- raw
我们拿磁盘来举例:
1 | package main |
执行结果:
1 | ./a1.go:33:12: cannot use diskType (type string) as type DiskFormat in argument to createDisk |
创建磁盘传参的时候, 我传递了一个string "a", 但是实际参数需要的数据类型为DiskFormat, 如果你非要使用自定义字符串传参, 那么你需要类型转换, 就像以下这样:
1 | func main() { |
但是更推荐的做法是使用预定义的常量来传参
1 | func main() { |
别名应用场景
别名的一个典型的应用场景是重构项目. 重构项目时, 可能会有代码使用老包中的方法, 也可能会使用扩展的新包中的方法. 使用别名可以灵活的”继承”原数据类型的所有方法, 并做扩展.
总结
别名的本质是一个数据类型的不同的名字. 比如我有一个中文名叫极地瑞雪, 我还有一个英文名叫PolarSnow, 英文名就是中文名的一个别名而已, 实际本尊只有一个. 极地瑞雪新学了个滑雪的技能, PolarSnow新学了个游泳的技能. 本质上, 就是我学会了 滑雪 和 游泳, 极地瑞雪和PolarSnow都可以施展这两项技能
定义全新类型真的就是全新类型, 不夹带任何原数据类型的方法. 就好比是我的克隆人, 从头培养, 从吃饭睡觉打豆豆开始培养, 我现在已有的任何技能, 都和克隆人没有任何关系. 克隆人学会了特殊技能也跟我本尊没有任何关系. 注意, 我的吃饭方法和克隆人的吃饭方法可以同时存在, 各自有各自的吃饭方法. 但是别名是不允许同名方法的情况存在的
etcd 灾难恢复
etcd的灾难恢复, 需要使用到快照文件, 本质是一次恢复快照的操作. 当etcd集群的大多数节点永久失联或短时间内无法继续正常使用时, 要想恢复etcd集群的服务, 需要执行etcd的快照恢复操作. 注意v2和v3版本数据恢复是两码事儿, 本篇重点介绍v3版本的数据备份和恢复
实验环境
前篇文章中留存的实验环境:
1 | 1161d5b4260241e3, started, lv-etcd-research-alpha-1, http://192.168.149.63:2380, http://192.168.149.63:2379 |
本篇文章将以此环境为基础, 使用备份的快照文件, 创建新的集群
整体步骤
- 创建快照文件
- 将快照文件分发到新集群的每一台主机上
- 使用 etcdctl snapshot restore 命令启动临时逻辑集群, 在新的数据目录中恢复数据
- 使用新的数据目录, 启动etcd服务
创建快照文件
在此假设集群中的5个节点, 仅剩192.168.149.60存活, 我们需要首先在存活的节点, 将数据导出(快照)
当然, 正常情况下, 生产环境会定期对etcd做快照备份, 对于这种情况, 直接拿最新的一份快照恢复即可
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.60:2379 snapshot save snapshot.db |
分发快照文件
第二步, 需要分发快照文件到新集群的机器上. 结合在我目前的环境中, 我需要把该快照文件发送到
- 192.168.149.61
- 192.168.149.62
- 192.168.149.63
- 192.168.149.64
在实际环境中, 可能另外四台, 或者原集群全部主机都无法使用, 此时需要将之前备份的快照文件, 从备份服务器下载到组建新集群的各个主机上
1 | scp snapshot.db root@192.168.149.61:/var/lib/etcd/ |
恢复快照
在 192.168.149.60 上执行
1 | cd /var/lib/etcd |
执行结果
1 | 2019-06-14 14:47:34.172213 I | etcdserver/membership: added member 6914761fd26729d7 [http://192.168.149.62:22380] to cluster c1cdf0b2061f8dcc |
在 192.168.149.63 上执行
1 | cd /var/lib/etcd |
执行结果:
1 | 2019-06-14 14:49:23.896672 I | etcdserver/membership: added member 6914761fd26729d7 [http://192.168.149.62:22380] to cluster c1cdf0b2061f8dcc |
在 192.168.149.61 上执行
1 | cd /var/lib/etcd |
执行结果同上
在 192.168.149.62 上执行
1 | cd /var/lib/etcd |
执行结果同上
在 192.168.149.64 上执行
1 | cd /var/lib/etcd |
执行结果同上
本步骤操作, 将快照中的数据写入到指定的文件夹下, 并写入新集群的元数据信息. 这里需要注意的是, 快照中的数据是干净的数据, 不包含原节点的节点ID和集群ID等元数据信息. 执行 restore 操作后, 集群信息由命令后面的参数决定, 所以后续所有的节点, 仅需要指定新的数据目录启动即可, 集群信息可不指定, 因为已经写入到db中.
启动新集群
修改etcd 配置文件, 指定新的数据目录来启动服务. 在我这里的实验环境中, 由于老etcd集群都在正常运行中, 我这里通过指定不同的端口, 在原有的5台机器中启动第二套新集群, 验证恢复操作
在 192.168.149.60 上执行
1 | 创建新的配置文件 |
其他四台以此类推…
检查原集群和新集群成员
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.63:2379 member list -w table |
注意v2与v3区别
官方不建议v2和v3混合使用, 也就是说, 如果你既有v2的存储需求又有v3的存储需求, 最好应该是用两个独立的集群将需求隔离开. 在备份恢复这个操作上, 也充分体现了v2 v3不要混用的重要性. 因为以上操作都是针对v3版本的备份和恢复. 即使备份的etcd集群中存在v2的数据, 在使用该方案恢复后, v2的数据将不会出现在新的集群中.
如果你需要针对v2版本做备份和恢复, 可以参考官方文档:
https://etcd.io/docs/v2/admin_guide/#disaster-recovery
大致步骤如下:
- 使用 etcdctl backup 命令备份数据到新的目录
- 使用新的目录, 以
--force-new-cluster的模式指定新的目录, 启动单节点etcd服务 - 如果需要恢复的是一个集群, 你需要先执行
ETCDCTL_API=2 etcdctl member update命令更新 - 最后按照正常运行时配置添加节点即可
etcd 添加之前已删除过的节点
场景: 当etcd集群中的一个节点, 由于主机故障, 被迫临时下线时, 为了保证etcd集群的健壮性, 会先删除掉该故障节点后, 再补位新的节点顶上去. 当故障机器经历了N天辛苦的修复后, 重新上线了, 此时需要将该台机器重新加回到etcd集群中
实验环境
在前面两篇文章的实验中, 一个原始的etcd集群如下
- 192.168.149.60
- 192.168.149.61
- 192.168.149.62
将 192.168.149.60 迁移到了 192.168.149.63
将 192.168.149.61 替换掉换成了 192.168.149.64
所以我这里的实验环境中, 已经有两台曾经服役过的etcd节点, 本篇文章将介绍如何将原节点重新加回到集群中
整体步骤
- 确认待添加的节点, etcd服务是停止的状态
- 删除etcd数据目录 member
- 执行运行时配置, 按正常添加一台新节点执行
- 更新配置文件, 启动etcd服务
Step 1: 确认状态
保证待添加节点的etcd服务状态为down
Step 2: 删除数据目录
1 | 去配置文件中, 找你的数据目录 |
Step 3: 添加节点
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.62:2379 member add lv-etcd-research-alpha-0 --peer-urls="http://192.168.149.60:2380" |
Step 4: 更新配置文件, 启动服务
按照上一步添加集群成员的回显, 修改配置文件(由于该台主机曾经就是etcd集群中的一员, 所以配置文件中仅需要修改回显中的关键参数即可)
修改完配置文件, 启动服务
1 | systemctl start etcd |
集群状态:
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.62:2379 member list |
第二个节点也依照此方法炮制
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.62:2379 member add lv-etcd-research-alpha-2 --peer-urls="http://192.168.149.61:2380" |
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.62:2379 member list |
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.62:2379,http://192.168.149.60:2379,http://192.168.149.61:2379,http://192.168.149.63:2379,http://192.168.149.64:2379 endpoint status -w table |
总结
重新添加之前已删除的节点的关键之所在就是删除数据目录, 因为数据目录中还保存这节点ID和集群ID等信息, 带着这些信息是无法通过校验添加到集群的
etcd 替换扩容节点
etcd 替换节点的本质就是添加一个新的实例, 再删除一个已有实例, 以完成替换. 如果替换的是一台已经无法正常运行的主机, 你需要先删除掉故障节点, 然后再正常添加一个节点.
实验环境
1 | +----------------------------+------------------+---------+---------+-----------+-----------+------------+ |
替换需求节点: 192.168.149.61 替换成 192.168.149.64
替换总体步骤(先添加, 后删除)
- 执行etcd运行时配置命令, 添加节点, 注意记录回显
- 在新机器上使用上一步首先的参数, 启动etcd服务
- 删除需要替换的节点
Step 1: 执行运行时配置, 添加节点
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.61:2379 member add lv-etcd-research-alpha-4 --peer-urls="http://192.168.149.64:2380" |
查看当前集群成员
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.63:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 member list -w table |
Step 2: 根据回显参数, 启动服务
在任意已运行节点执行
1 | 可以先将一个已存在节点上的配置文件, 发送到新的节点 |
在新节点执行
1 | 编译配置文件, 将上一步运行时配置的回显结果中的参数, 替换到配置文件中 |
同理, 由于是copy过来的配置文件, 以下参数也需要做响应的修改:
1 | ETCD_LISTEN_PEER_URLS |
由copy原主机IP, 修改到目标主机IP地址, 修改完成后, 启动etcd 服务
1 | systemctl start etcd |
集群状态:
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.63:2379,http://192.168.149.62:2379,http://192.168.149.61:2379,http://192.168.149.64:2379 endpoint status -w table |
注意: 执行endpoint status查询时, 记得在--endpoints参数中, 加上新节点的地址http://192.168.149.64:2379
Step 3: 删除需要替换的节点
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.63:2379 member remove e6f45ed7d9402b75 |
节点已被删除, 节点被删除后, etcd服务会被关闭, 日志中将出现如下信息:
1 | removed member e6f45ed7d9402b75 from cluster 2c25150e88501a13 |
此时, 你需要保证该节点的etcd不会自动启动, 开机启动, 重新启动. (虽然即使启动也不会再次成功加入到集群, 但是为了避免不必要的错误, 还是需要保证挂的彻底一些, 最好将数据目录也一并删除)
替换故障节点
以上的操作, 前提是集群节点全部正常的情况下, 才能执行member的操作, 当其中一个节点故障时, 你将无法直接新增节点, 你需要先删除故障节点, 然后再执行新增节点的操作
etcd 节点迁移
etcd 的节点变更有两种方式变更, 一种是数据迁移, 一种是通过增加新节点, 同步数据完成后, 删除老节点来实现的. 本篇文章介绍前者, 通过数据目录的迁移, 来实现etcd节点的迁移
实验环境
当前etcd集群信息
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.60:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 member list |
1 | > ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.60:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 endpoint status -w table |
本次目标是将 192.168.149.60 节点迁移到 192.168.149.63 节点
总体迁移步骤
- 先在
192.168.149.60上停止etcd服务, 如果该进程已经挂掉, 也就省去了停止etcd的步骤了😆 前提是你必须要保证, 它挂的很彻底, 不要迁移了一半又自己活过来… - 从老机器上迁移数据到新机器对应目录
- 在任意节点执行member update操作, 更新peerURLs信息为新机器的 IP:Port
- 从老机器上将配置文件一并拷贝到新机器, 修改成新机器IP地址后, 保证指向的数据目录正确, 启动即可
Step 1: 停服务
在需要迁移的节点上, kill掉etcd的进程, 如果条件允许, 不要-9, 优雅关闭优先
1 | systemctl stop etcd |
此时查询集群状态:
1 | > ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.60:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 endpoint status -w table |
192.168.149.60 节点已经处于失联状态
Step 2: 迁移数据目录
在192.168.149.63上执行(预建数据目录)
1 | mkdir -p /var/lib/etcd/default.etcd |
在192.168.149.60上执行(打包发送)
1 | tar -cvzf member.tar.gz member |
在192.168.149.63上执行(解压)
1 | cd /var/lib/etcd/default.etcd/ |
Step 3: 更新member信息
在任意一个节点执行, 已更新原节点 peerURLs 信息
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.61:2379 member update 1161d5b4260241e3 --peer-urls="http://192.168.149.63:2380" |
--endpoints http://192.168.149.61:2379 因为 192.168.149.60 节点已停止服务, 所以这里需要选择一个其他的endpoint节点来对集群进行操作
1161d5b4260241e3 是 192.168.149.60 的节点ID, 如果忘记的话, 可以执行 member list查看
回显显示命令已正确执行, 查询状态如下:
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.60:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 member list -w table |
可以看到第一行, PEER ADDRS 已经正确更新成为 http://192.168.149.63:2380, 但是后面的 CLIENT ADDRS 依然是原来的 http://192.168.149.60:2379. 这个不用担心, 等新的节点启动后, 这个值就会变成正确的地址
Step 4: 在新节点启动服务
在新节点启动服务之前, 记得把配置文件, 从老节点拷贝过去. 拷贝完成后, 一定要参数进行修改.
1 | 以下两个参数如果指定了: 0.0.0.0 就无需更改, 如果是精确指定每个IP地址, 则需要将IP60更改为63 |
以上修改的参数中, ETCD_LISTEN_PEER_URLS ETCD_LISTEN_CLIENT_URLS ETCD_ADVERTISE_CLIENT_URLS 是最重要的参数, 一定要和新机器的IP地址匹配
因为etcd是运行时重新配置, 另外两个 INIT 的参数虽然在服务启动的时候不再起什么作用了, 但是为了后期看到配置文件后不知道迷茫, 也最好都统一修改到新机器的IP地址
同理 ETCD_INITIAL_CLUSTER_STATE="new" 参数可以保留, 因为不起作用
启动etcd服务
1 | systemctl start etcd |
集群状态:
1 | ETCDCTL_API=3 etcdctl --endpoints http://192.168.149.63:2379,http://192.168.149.62:2379,http://192.168.149.61:2379 endpoint status -w table |
可以看到”新的集群” RAFT INDEX 已经一致, 表示新节点192.168.149.63已经追上集群数据.
PEER ADDRS 和 CLIENT ADDRS 也均为正确的地址
此时, 节点迁移正确完成
总结:
这种迁移方式基本仅在待迁移的节点还能正常登陆, 还能正常访问数据目录的前提下进行. 如果机器已经挂掉, 无法访问到原有数据, 那么这种方式并不合适. 迁移嘛, 都正常才能迁移, 不正常的迁移叫故障恢复😆